This article describes a new capability that I added to SEGGER emRun, now available in Embedded Studio 6, to support real-time dynamic storage allocation. These enhancements were inspired during my development of a chess engine, and I’ll describe some of the engine design and why emRun now offers a new allocator.
If you’re just interested in the real-time allocator, jump right to it!
Why write another chess engine?
A good question. Each Christmas, I pick an interesting project to explore over the break, without distraction. For the ’21 holiday season, I wanted to improve my chess and had planned to use ChessUp for that, a Kickstarter project I backed earlier in the year. But ChessUp dragged and, sadly, wouldn’t arrive in time. A small consolation is that the ChessUp guys are using SEGGER production tools to program and test the units!
Rather than improve my chess, how hard could it be to write my own chess engine? Turns out, it’s trickier than expected!
Choosing development tools
My day-to-day development happens in C, C++, and all forms of Arm and RISC-V assembly language. As Embedded Studio supports modern C++ with an up-to-the-minute template library, I decided that I would take the opportunity to write in C++ using STL.
For rapid development I decided to use a combination of emWin and embOS in simulation under Windows. When complete, the code would simply work on an embedded target by recompiling using Embedded Studio.
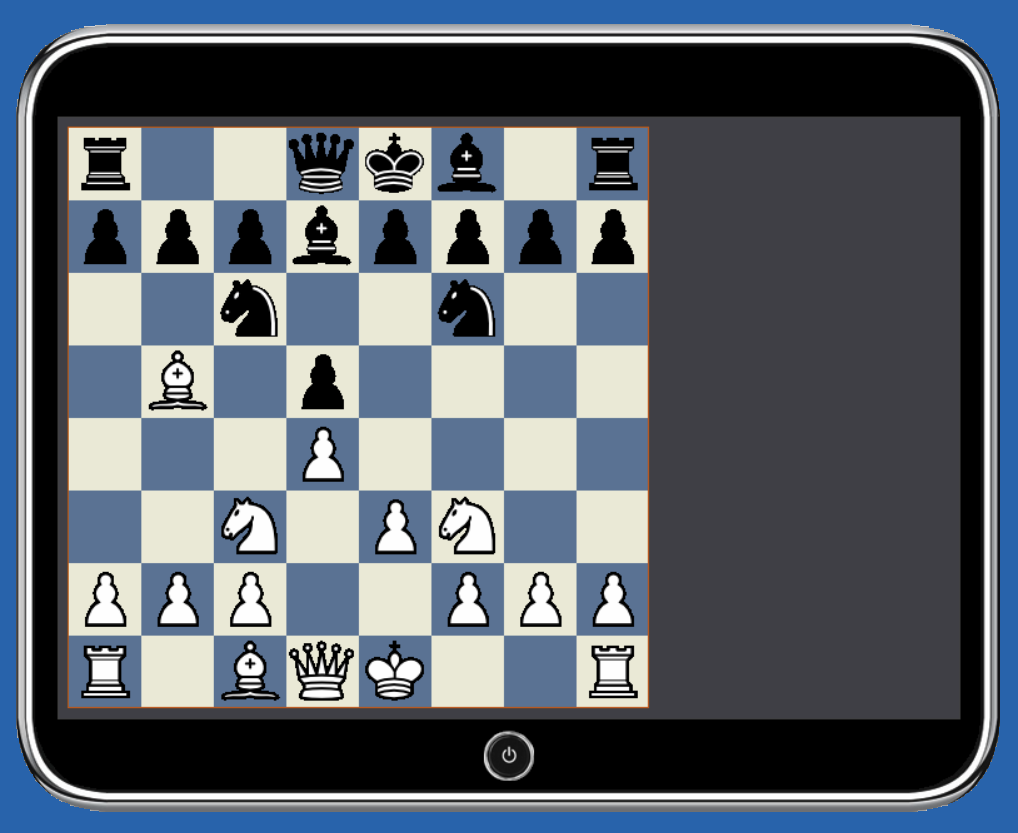
Here’s the current version of emChess playing itself on Windows, without the aid of an opening book (click to expand).
Using C++ STL in the engine
My aim was to write an engine that was correct, rather than be the last word in performance. I didn’t need something that would accept, or propose, illegal moves. Because I use STL extensively elsewhere, such as the SEGGER Linker, using STL as part of the engine was very natural.
I’m going to take a whirlwind tour of the main data structures emChess started with, implemented as STL containers.
The board, piece lists, and move lists
I decided to choose a classical 8×8 array of pieces to describe the board position and a set of piece lists to quickly look up a piece by type. A piece list is simply an STL std::list<Piece>. Piece lists are modified after captures and promotions, and iterating STL piece lists is easy with C++’s new for-loop over iterable containers.
for (auto p: Board.Pawns) GenPawnAttacks(p);
The move generator surveys the board position and returns a list of valid moves that can be played in that position, without any evaluation of whether they are good or bad. As you might imagine, a list of moves is realized as a std::list<Move>. When a new move m is generated, it’s recorded with:
MoveList.push_back(m);
The transposition table
emChess uses a transposition table that records, for a specific board position, what its evaluation is, i.e. whether white or black is better, and by how much. This is an important data structure that speeds up searching because identical positions can be reached by different move orders, and the evaluation of these positions is always the same.
The transposition table maps a board position to its evaluation. In fact, it maps a Zobrist hash of the board position to an evaluation as comparing entire board positions for equality is expensive. This is a similar concept to the cryptographic hash of a message: two board positions differing in the position of a single piece produce wildly different hashes; and it’s unlikely that two board positions produce the same Zobrist hash, commonly known as a collision.
The transposition table is described as an STL std::map<U64, int>, mapping a 64-bit Zobrist hash to its evaluation in units of centipawns. Each time a position is recorded, the map needs updating. As an STL map is commonly implemented as a tree, a new tree node needs to be created on each insertion, and freed when it is no longer relevant. So, lots of heap operations.
The unpleasant issue of time control
Behind the scenes, each manipulation of an STL container requires dynamic allocation and deallocation of memory. During play, the memory allocator gets a thorough workout, allocating and deallocating blocks of varying sizes in random fashion. This leads to a rather problematic issue.
When playing a rapid, blitz, or bullet game of chess, it is vitally important that you don’t run out of time: you must not take too long over a move. For a time-controlled game, I simply divided the game duration by 50, an initial estimate of number of moves in the game, to get the time to allocate per move. An embOS timer is scheduled at the start of the search and later expires, causing the search to abort, and the “best move found so far” is played.
From time to time, I found some moves were taking longer than expected. If you can’t accurately predict the timing for a move, or not have a search aborted when the timer expires, it is unsettling.
What I found is that when searching deeply, the standard memory allocator will sometimes take much longer than I expected to allocate or deallocate memory. This is because memory becomes fragmented when managing allocation requests for blocks of different sizes. The standard allocator has a single free list and searches that list for the best fit: all of it. And when freeing, it inserts the freed block in address order by traversing the free list and coalescing, so freeing a block at lower addresses is faster than freeing a block at higher addresses, in general.
Now, I knew that the best-fit heap did this, but I hadn’t realized that managing an 8 MB heap would be quite so problematic when running my engine. It’s not so common for embedded applications to rely heavily on dynamic storage, but here I am with an application that does using C++ and STL because emChess triggers allocations and deallocations continuously, hundreds of thousands of allocation/deallocations per second.
SEGGER’s new real-time allocator
I surveyed other toolchains to see what they typically use for an allocator. It seems that silicon vendor toolchains, and some commercial toolchains, use Doug Lea’s dlmalloc, which is well regarded. However, even this allocator doesn’t guarantee constant-time allocation/deallocation and, therefore, would seem an awkward fit for a real-time system.
This single issue prompted me to write what I had been considering for some time: a new, real-time allocator that takes constant time for both allocation and deallocation. To achieve this, the heap manager has no loops, is straightline code for all requests, and is “good fit” rather than “best fit”.
The new allocator uses the two-level segregate fit model, which suits microcontrollers nicely. It is also very small, taking just 664 bytes of code for initialisation, allocation, and deallocation facilities on a Cortex-M4. An allocation worst case is 125 executed instructions, and a deallocation 95 executed instructions on that processor. All the time. Every time.
You might wonder about heap fragmentation. The new real-time heap is practical and is not unduly fragmented by requests of varying sizes, which is an excellent property.
How does SEGGER’s new real-time heap compare to Doug Lea’s malloc()? Well, as that allocator does not provide constant-time allocation, a comparison doesn’t seem useful. However, this paper shows just how bad dlmalloc performs in the worst case, and it’s not pretty.
Comparing code size is far easier. I measured dlmalloc’s deployment in a well-respected commercial toolset: 5332 bytes of code for initialisation, allocation, and deallocation facilities on a Cortex-M4, that’s 8x the size of the real-time allocator’s code from The Embedded Experts.
Performance
Heap performance can be measured in many ways and is ultimately dependent upon the allocation and deallocation profile of the application. But for the chess engine here, the real-time allocator’s performance is better.
In Embedded Studio, switching between allocators to compare performance couldn’t be simpler: edit a project setting in a dropdown:

Using the standard heap, running the move generator benchmark on a 168 MHz Cortex-M4, the timings are:
Starting position Depth 1: 1.354 ms OK 20 nodes 14771 nodes/s Depth 2: 27.591 ms OK 400 nodes 14497 nodes/s Depth 3: 592.270 ms OK 8902 nodes 15030 nodes/s Depth 4: 13058.626 ms OK 197281 nodes 15107 nodes/s
The real-time heap performance is better:
Starting position Depth 1: 0.944 ms OK 20 nodes 21186 nodes/s Depth 2: 18.923 ms OK 400 nodes 21138 nodes/s Depth 3: 405.463 ms OK 8902 nodes 21955 nodes/s Depth 4: 8949.222 ms OK 197281 nodes 22044 nodes/s
The overall benefit for this application is a performance increase of 46%, not too bad!
Conclusion
SEGGER’s new real-time allocator is small, delivering excellent performance for real-time systems coded with C or C++. It is now practical to use STL in real-time systems.
Applications using many objects in C++ experience a performance gain using the SEGGER real-time allocator. How much depends on the application, but it makes emChess deliver its moves on time. Every time.