Many people think that in today’s world, the size of a program does not matter. In many cases, that is not true, especially in the world of embedded computing systems. I explain why and introduce a benchmark that makes it possible to easily compare the code-size efficiency of different tool chains (Compiler, assembler, linker, run time library) even across different CPUs and architectures.
Why does size matter?
In embedded systems, programs need to fit into a given flash or RAM. If they do not fit, the program can either not be used or not get the desired functionality, sometimes meaning new features cannot be added. In other cases, bigger chips with more memory are available, but at a higher price. In today’s world, a lot of chips still have only 64 KB of flash memory or the program needs to run from a RAM which is limited in size. Another reason why programs should be small is that in bigger systems with caches, the cache can be used more efficiently if the program is smaller. In a smaller program, cache lines need to be evicted much less frequently, resulting in higher execution speed. Also, firmware updates complete faster, especially when delivered over low-bandwidth connections. (Which can also be a reason to use compression…)
Benchmarking speed
There are a lot of benchmarks out there, which all seem to be doing the same thing: Measure performance, execution speed. They are called Coremark, Drystone, …
This is certainly interesting in many cases, however, code size can be equally or sometime even more important. Almost every compiler can optimize for either speed or size (some also for a mix of both, usually called “balanced”). It is easy to make a program faster (up to a point) by using loop unrolling and inlining. So to make a fair comparison, one should always also look at the size of the generated program.
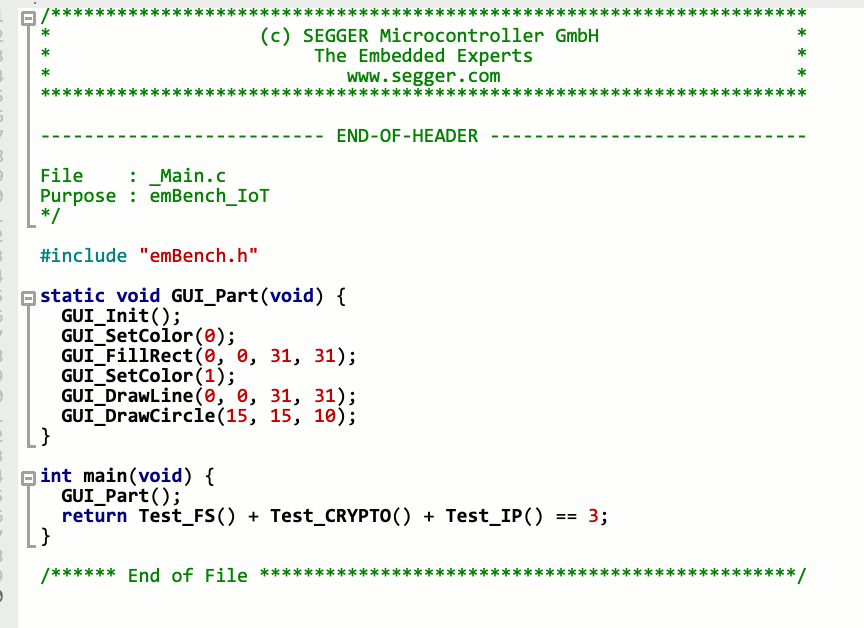
Benchmarking size – emBench-IoT
We wanted to make sure our benchmark is typical for an embedded system and is 100 % portable. So we have taken components that we know are typically used in embedded systems and have made them part of our benchmark.
We use parts of:
- emWin, our GUI
- emNet, our TCP/IP networking stack
- emCrypt, our cryptography library
- emFile, our file system
All of these are used in a way that the tool chain has no chance to optimize away anything.
The emWin component is drawing into the frame buffer (a volatile RAM area),
the other components perform a rather complicated self test which then ends up returning a result, which is then used in the main program.
Results
We have been using this test internally for quite some time, to benchmark the SEGGER Linker, SEGGER Compiler, and SEGGER run-time library against itself (different versions) as well as Arm vs. RISC-V.
This allowed us to monitor the progress of all of these components.
It also enables us to see the benefit of using LTO (Link time optimizations).
To give you a glimpse, here are four results, for Arm (Thumb-2) against RISC-V (RV32IMAC), with and without LTO.
IDE Build Config Code RO Data Total
================ ====================== ======= ======= =======
ES ARM V6.34a LTO 64376 18703 83079
No LTO 76920 18952 95872
ES RISC-V V5.34 LTO 77106 19145 96251
No LTO 85266 19347 104613
It shows a few things…
- Arm Thumb-2 has a higher code density than RISC-V (RV32IMAC requires between 16 % to 20 % more program memory)
- LTO can significantly reduce program size (here between 8 and 15 %)
The results are consistent with what we have found with other, real world applications.
And on a similar note:
We have benchmarked other tool chains. We have done our best to be fair, by selecting options that should result in the smallest program size, such as high size optimization, small run time library where available, Multi-File compilation, …
The closest competitor reached 87 026 bytes (also on Arm Thumb-2), which is still 4.8 % bigger than the size of the program created by Embedded Studio.
On a related note: When benchmarking tool chains, one interesting experiment is to take an empty project, an empty main() and see how big the generated program is. With Embedded Studio and emRun, we have put emphasis on making sure that only code which is actually needed is linked.
See also my posts
Smallest hello world (a real hello world program in 117 bytes!)
Every byte counts – the 100 byte blinky challenge (A functional blinky application in “C”, less than 100 bytes)
Code density of Embedded Studio
We are not surprised to see that Embedded Studio generates smaller programs than applications generated with free tool chains.
What did in fact somewhat surprise us is that Embedded Studio generates smaller programs than all commercial tool chains we have tried.
If code density is important to you, you should download Embedded Studio and built your application with it. Embedded Studio offers the full functionality for non-commercial use and evaluation. It should not be hard to set up a project, and give your application a try.
We are always interested in feedback, and especially in areas of potential improvement, so if you have an application which is smaller when built with another tool chain, we would like to hear about it.
And if you can confirm that it is smaller, we also would not mind hearing from you…
Availability of emBench-IoT
We are licensing emBench-IoT to select customers.
It can be quite useful in a variety of ways, for comparing code density of an architecture, a run time library or a compiler, or the total combination.
It can of course also be used to see how useful in terms of size a particular optimization of a CPU can be (by adding special instructions). Obviously, this is a little more tricky, as it requires a compiler which takes advantage of these instructions.
Interested in emBench-IoT? Please contact us: info@segger.com.