In the previous post, Rolf described some of the progress that we have made on the brand-new SEGGER linker. In this post I examine the gnarly problems with the GNU linker and how they are easily solved by the SEGGER linker. A follow-up post will examine more of the linker’s capabilities.
The SEGGER linker is now integrated into Embedded Studio, our premier development environment, and has been tested for compatibility with Embedded Studio and Ozone, the J-Link debugger. However, this version is not yet released, it’s tentatively scheduled to happen sometime this month (Oct 2017), as we would like to use it internally first, to “get some hours on it”.
What’s wrong with the GNU linker?
The linker is the most unglamorous part of a development environment: it acts to stitch the program together from all the separately-compiled sources, and prepare it for execution. Nothing else. Simple, yes?
For host systems, such as Windows and Linux, linking is conceptually straightforward but has complexity baked-in for versioning, ABI compatibility, and shared libraries / DLLs, and so on.
Linking for bare-metal embedded systems swaps shared library baggage for the problem of fitting an application into a small microcontroller with a multitude of memory regions. If the end product has an extended life with regular updates then feature creep tends to make the firmware expand to fill all available space. When this happens, figuring out where you can trim the application and where your RAM is spent becomes important.
Unfortunately, the GNU linker really doesn’t help when developing embedded systems:
- the map file is impenetrable
- the linker script looks daunting
- features to flow code and data over multiple RAM or flash regions whilst keeping away from configuration areas and adding a CRC is nonexistent.
- Placing items at fixed memory addresses is a mind-bending puzzle that percolates up into source code.
Using the GNU linker is just challenging: it’s too inflexible in its placement model and link-editor scripting language. When the rubber hits the road, having a capable linker rather than a make-do linker really can make all the difference to a project.
So, let’s dive right in and show what the SEGGER linker can do!
Flowing code around a configuration area
Some microcontrollers have their flash programmed with calibration values at the factory which should not be erased; some have flash security keys at the start of a flash page; and some applications just need to keep out of configuration areas that are programmed during device production and test.
Let’s take a typical example where some flash is defined as a configuration area. The first page of flash is typically used for exception vectors and can’t be used, so engineers invariably choose the final one or two pages to have the maximum contiguous linear address space for code and read-only data. Over time code grows and no longer fits, a bigger device is placed on the board, but legacy production and field updates means that the configuration area must remain in its original position: now plumb in the middle of the flash area. Fantastic. Welcome to legacy, I’m looking at you MSP430X…
The GNU way (or, in fact, the old way)
Using GNU ld this presents a massive problem: two areas to populate with code and data and a big, greasy configuration section slap-bang between them. The only way is to partition your read-only data and functions into different non-default sections so that these sections can be gathered together as units and manually placed. In a synthetic link-editor script you would give directions something like this:
define region LO_FLASH = [ 0x00000000 to 0x0000FFFF-256 ];
define region HI_FLASH = [ 0x00010000 to 0x00020000 ];
place in LO_FLASH { section .lo_text, section .lo_rodata };
place in HI_FLASH { section .hi_text, section .hi_rodata };
This directs the linker to place the “low” code and data into the first 64k minus 256 bytes (where the configuration area is), and to do the same for the “high” code and data.
Assistance from the IDE
Now, if you are fortunate and have a capable IDE, such as Embedded Studio, your IDE will help with this task by enabling you to set the code and data section names on a per-file, per-folder, or per-project basis. So you could organize the project into two logical folders (note: different from “disk folders”), place the sources you want in low memory in one folder, and the sources you want in high memory in the other:
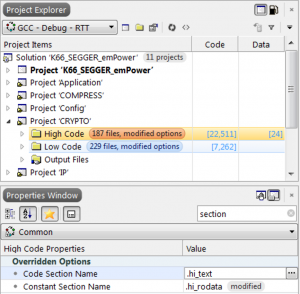
Moving code and data between the two areas is now just a matter of moving source files from one logical folder to another and letting the IDE sort it out.
Of course, the issue is that this doesn’t scale too well, you’ll be forever moving files around, finding that you need to artificially break up sources to get finer granularity over where functions and data are placed.
There must be a better way, because well, aren’t computers supposed to help us with automation and do all the heavy lifting?
The SEGGER way
Well, yes, the SEGGER linker will do this for you—automatically! Here’s how:
define region FLASH = [ 0x00000000 to 0x0000FFFF-256 ]
| [ 0x00010000 to 0x00020000 ];
place in FLASH { section .text, section .rodata };
That’s it. No direction on how to break things up into low and high areas. You declare a disjoint region of memory with one area having a chunk of 256 bytes removed and the second area following it.
Then you place your code and data into that flash area and let the linker do the section placement for you. Job done, move on.
Placing functions or data at a fixed address
For whatever reason, customers always want to do this. This problem is related to the “keep away” problem described above, but is more complicated as something needs to be placed at a fixed address and worked around.
Let’s take the example of placing a function at address 0x8000 inside a 64k flash region. How would you do this with the GNU linker? Well, to cut to the chase, you can’t do it automatically because (in general) you don’t know the size of the function if it’s compiled by the C compiler, and its size will invariable change depending upon compilation options used.
But let’s take a shot at it. If you have better suggestions, please let me know.
A simple GNU linker script
In general a much-reduced GNU linker script for a small Cortex-M device looks like this:
SECTIONS {
. = 0x00000000;
.vectors : { *(.vectors) }
.text : { *(.text) }
.rodata : { *(.rodata) }
. = 0x20000000;
.data : { *(.data) }
.bss : { *(.bss) }
}
This instructs the linker to place the vectors at address zero, followed by all the code, followed by all the read-only data. Then it’s instructed to place all initialized data at 0x20000000 followed by zero-initialized data.
Note that to get our vectors placed first we need to define a section for the vectors, separate from the .text section that holds code. The linker wildcard “*(.text)” commands the linker to gather together all the .text sections from all the input files and merge them into a single output .text section. With this in mind, you can see that there is no guarantee that the input .text section containing the vectors will be placed at zero as any input .text section might be placed first. (Yes, for those of you versed in GNU linker scripts, I know there is a way to specify that the .text section of a specific file should be placed first…)
Returning to our problem, the only way to guarantee that a function is placed at an address is to compile it into its own named section…
void __attribute__((section('.myfunc'))) my_placed_function(void) {...
…and place it:
SECTIONS {
. = 0x00000000;
.vectors : { *(.vectors) }
.text : { *(.text) }
. = 0x00008000;
.myfunc : { *(.myfunc) }
.rodata : { *(.rodata) }
. = 0x20000000;
.data : { *(.data) }
.bss : { *(.bss) }
}
This will work with a small program: the code of the application will fit into memory all below 0x8000 and the code and data all fit. However, as soon as the code grows above approximately 32k, the GNU linker will complain that it can’t place .myfunc at address 0x8000 because it’s already occupied by code in the .text section. And we’re back to manually segregating code around 0x8000…
What simply works?
By now you expect that SEGGER’s solution will simply work. It’s OK but it’s not really optimal, and we’ll return to this.
First, we dispense with the attribute on the function and make sure it has external linkage so the linker can see it:
void my_placed_function(void) {...
Then the placement is made:
define region FLASH = [ 0x00000000 size 1m ];
define region RAM = [ 0x20000000 size 192k ];
place at 0x8000 { symbol my_placed_function };
place in FLASH { section .text, section .rodata };
place in RAM { section .bss, section .data };
The instructions here should be fairly clear:
- Selects the symbol my_placed_function and place it at
0x8000. - Gather all code and read-only data and place it in the unused portion of the flash region
- Place initialized and zero-initialized data in the RAM region
Notice that the linker takes care of placing code into memory and working around absolutely placed items: you don’t need to “make a hole” for the function to fit into, the linker knows how big the function is, where it’s placed, and the specification of what to place where, and it simply works on the problem and solves it for you.
The ideal solution
Software engineers work with source code more than they do with linker scripts. The above solution works, but it has some minor drawbacks for some people:
- It’s not clear from source code that a function is placed absolutely, you must look at the linker script
- You need to write the linker script and place the function yourself
- The function must be a linker-visible symbol
- It’s very simple to change the name of the function in the source code and forget to make a corresponding change in the linker.
The solution for this is to use the compiler for the placement specification…
void __attribute__((section('__at_0x8000'))) my_placed_function(void) {...
…and not pollute the linker script:
define region FLASH = [ 0x00000000 size 1m ];
define region RAM = [ 0x20000000 size 192k ];
place in FLASH { section .text, section .rodata };
place in RAM { section .bss, section .data };
The linker automatically interprets section names that end with the particular sequence __at_hex as an absolute placement to be made. Simple and effective.
Conclusion
I’ve explored some of the SEGGER linker’s capabilities here, the ones that address common problems facing embedded software engineers. Follow-up posts will expose more features of the SEGGER linker and describe its laser-focused map file.